
Single Region Risk- How the AWS Outage Disrupts Operations

Introduction
It was October 20, 2025, when something unexpected happened! Amazon Web Services (AWS) experienced a massive outage in its US-EAST-1 region. It disrupted millions of users and numerous businesses across the world. Whether it is a streaming giant, Netflix, or B2B SaaS providers, all experienced the domino effect instantly.
Though the AWS outage was gone within hours, it had left its scars on many global enterprises. This unwanted incident left a sharp reminder of the fact- resilience is not optional and over-dependence on the cloud is not beneficial. This post discusses the timeline, root causes, business impact, and strategic lessons from this outage. We will also dig deeper into the ways you can make your organization’s cloud architecture future-proof against such disruption.
Before moving ahead, it is interesting to see the rise of the cloud market amid the AI boom.
Timeline and Scale of AWS 2025 Outage
Many companies have moved to the cloud in recent years, and other companies follow suit. This trend has brought an exponential increase in the cloud market. As per the Synergy Research Group report, this market is expected to cross USD 400 billion by the end of 2025. This massive growth shows a CAGR of over 25 percent. The following graph shows the growth of the global cloud market between 2017 to 2025.
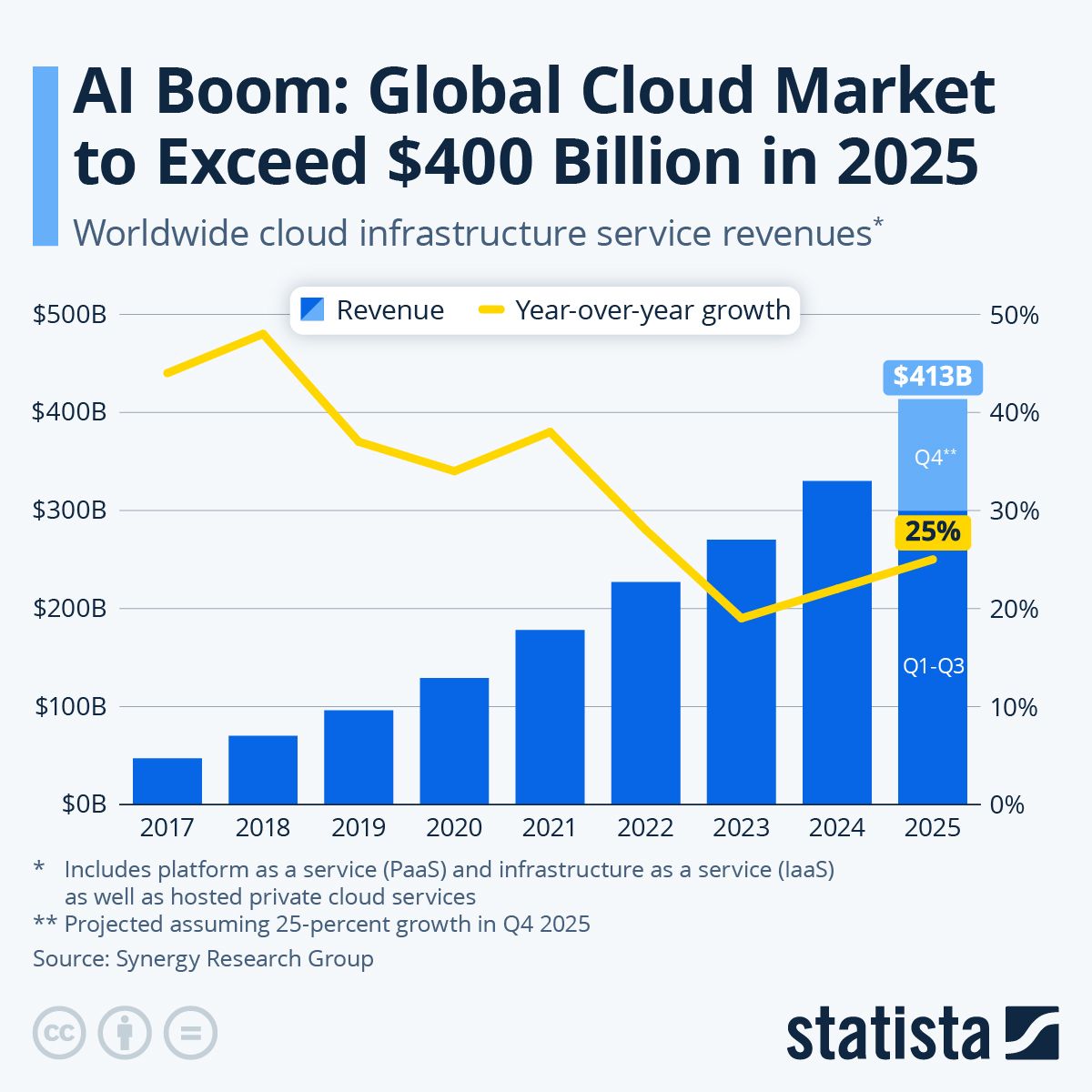
Source
AWS-based enterprises in the US-EAST-1 region were upside down with the beginning of the AWS outage early on October 20 (6.49 AM UTC). It started with issues with services, such as EC1, API Gateway, and DynamoDB. As per ThousandEyes’ analysis, latency and packet loss surged within the control plane of AWS, signaling a deep-rooted problem in infrastructure.
AWS engineers identified the DNS issue by 7.26 AM UTC and began implementing temporary solutions by 8.15 AM UTC. It enables some internal services to connect to DynamoDB. They could restore full DNS information by 9.25 AM UTC, and customers were able to establish successful connections between 9.25 AM and 9.40 AM UTC. However, new EC2 instance launches failed or experienced connectivity issues until 8:50 PM UTC, for over 11 hours after restoring the DNS.
Amazon’s various services, including Amazon Connect, AWS Security Token Service, and Amazon Redshift, experienced extended impact due to ripple effects through their dependencies. The scale of this outage was staggering, as businesses across the entire North America, Europe, and Asia were affected. Whether it is Slack or smart home devices, all went either offline or degraded.
This AWS outage showed how a single-region failure can cause damage on a massive scale due to cross-region service dependencies.
Causes of AWS Failure You Need to Know
AWS later identified the primary cause of this outage as a latent DNS race condition in the DynamoDB internal control plane. It created an overwhelming surge of DNS resolution requests, which throttled internal network components, resulting in authentication failures and timeouts. In other words, a small software bug triggered a network issue that spread across the entire AWS ecosystem.
The AWS outage spread rapidly due to the dependence of key services on the same underlying infrastructure. As internal AWS systems share networking and authentication layers, when one service fails, it affects others. Moreover, many enterprises deploy their workloads in US-EAST-1. This amplified the impact of the outage significantly. Though AWS patched the bug swiftly, it offered little about the reason behind the existence of such architectural coupling.
Let’s delve into the impact of this outage on businesses across different sectors.
Impact of Downtime on Businesses
The AWS outage had a vast impact that brought an economic shockwave. Global enterprises that rely on AWS-hosted applications experienced significant operational losses. For example, eCommerce companies faced order delays during peak periods. Streaming services like Netflix reported partial downtime. IoT platforms lost connectivity with devices. B2B SaaS providers could not authenticate user sessions or access various APIs related to AWS.
This downtime brought inconvenience to millions of customers and financial damage to businesses. It also gave fuel to a heated debate about vendor concentration risk and the vulnerability of depending on a single cloud provider.
Lessons for Resilience- How to Minimize the Impact of Outage
The key lesson learned from this outage is that companies need to build cloud resilience in the right way. Here are some useful tips for enterprises to reduce the impact of such outages-
1. Avoid Dependence on a Single Region
As they say, “Do not put all your eggs in one basket.” This outage has made one thing clear: the US-EAST-1 dependency proved costly. Therefore, it is better to adopt a multi-region strategy. Companies can deploy replicas of mission-critical workloads in different geographically isolated regions like US-WEST and EU-CENTRAL. Though it can increase cost, it is useful for maintaining business continuity during the outage.
2. Identify Hidden Dependencies
Let’s face it. Many companies that remained outside the affected region failed due to their authentication or monitoring tools relying on US-EAST-1 APIs. This indicates the necessity of identifying hidden dependencies. Organizations can use dependency mapping tools to find indirect connections and third-party dependencies on the cloud servers. This identification is useful for updating customers during the outage.
3. Strengthen Observability and Response
This is one of the best practices. When companies detect the issue quickly, they can recover it quickly. End-to-end observability using external monitoring tools can help companies detect anomalies independently. This can improve the response during instances of outage. The AWS outage has shown the importance of continuous monitoring and quick response to issues for companies, irrespective of their size.
4. Demand Transparency and Review SLAs
A partial disclosure of AWS highlighted a broader issue: limited customer visibility. It is, therefore, necessary to review SLA clauses around outage communication, failover processes, and response time. Companies can ask cloud service suppliers to bring transparency in disclosing incident root causes and prevention strategies. This may help address the circumstances during the outage.
5. Get Ready with Plan B
In the event of an AWS outage, it is necessary to have contingency plans in place for customer communication. Predefined communication strategies can ensure timely updates about the status of functionality and services. This can maintain people’s trust during outages. Netflix’s engineering team kept non-critical functions alive during an outage by implementing Plan B. Companies can maintain read-only modes or cached failovers to maintain partial services.
Simply put, it is essential to choose the right cloud solution provider with a proven track record and vast experience in offering high-end solutions.
Looking for the Best Cloud Hosting Services for Your Business Applications?
LET’S CONNECTRecommendations to Avoid Cloud Outage
This AWS outage has shown the fragility of cloud storage and services. As a reputable AWS managed services provider, we recommend the following steps to reduce the impact of an outage-
Opt for Hybrid Approach
It is better to avoid total dependence on a single cloud network. Companies should distribute workloads across AWS, Google Cloud, and Azure. A hybrid approach consisting of on-premise and cloud is also a nice option.
Automate Failover and Replication
Let’s face it. Human-triggered recovery is way too slow. It is, therefore, essential to implement DNS-based traffic failover and infrastructure-as-code for rapid failback. This can replicate the process quickly to minimize the impact.
Continuously Test and Audit Resilience
It is necessary to perform chaos engineering exercises and load tests regularly. It helps you validate the architecture’s ability to handle region-wide failures. Moreover, audit resilience is useful to resolve sudden outages.
Prioritize Redundancy
Core transactional workloads, including payments, authentication, and APIs, must have redundancy. This is specifically useful during the time of such an outage or downtime to continue non-critical services.
Establish Resilient Culture
Finally, you need to encourage a “failure-aware” culture. When the organization combines engineering, DevOps, and other teams for downtime planning, it becomes a business imperative. Leadership should consider this for the company.
As enterprises rely heavily on hyperscalers like AWS, we can expect that the shared responsibility model will become more complex over the period. Regulators have started to scrutinize cloud provider transparency, especially when outages harm critical infrastructure. It is fair to say that CIOs and CTOs need to consider a strategic approach that balances innovation speed with operational resilience.
Concluding Remarks
The AWS outage in October 2025 revealed the weaknesses of centralized cloud ecosystems. With this, it has given a blueprint for smarter and more resilient design. Preparing a contingency plan and resilient culture with less dependence on a single cloud network are some of the steps companies can take to manage such an outage.
Silicon IT Hub is a renowned cloud hosting provider. We offer top-notch cloud and DevOps services to meet the diverse needs of modern enterprises. Contact us to learn how our services assist you in simplifying the complexities of your business model.


 Have an Idea?Let’s Build It Together!
Have an Idea?Let’s Build It Together!
